| hbase 数据导出乱码 | 您所在的位置:网站首页 › hive数据导出到hbase › hbase 数据导出乱码 |
hbase 数据导出乱码
 前言
前言
hive提供了与Hbase的集成,是的能够在Hbase表上使用hive sql语句进行查询、插入操作以及进行join和Union等复杂查询、同时也可以将hive表中的数据映射到Hbase中。 当我们在使用hive时候,在数据量多的时候就会发现非常的慢,一个简单的sql都要半天,其实我们追寻他的原因很简单,首先他是把sql翻译成mapreduce来执行,然后mapreduce又是提交给yarn去运行,可以说过程漫长,加上mapreduce本身就足够慢,所以本文从集成hbase的方面来调优,或者说是加快查询速度,当然了,最后,还会探讨如何用sql语言去查询,毕竟hbase是nosql的。 官方配置文档地址 https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration这个是在hive的用户说明文档中。 配置1.修改hive-site.xml文件,添加配置属性 hbase.zookeeper.quorum node1:2181,node2:2181,node3:21812.修改hive-env.sh文件,添加hbase的依赖包到hive的classpath中。 export HIVE_CLASSPATH=$HIVE_CLASSPATH:/opt/bigdata/hbase/lib/*注意:1.这里后面的路径换成自己的安装目录2.hive-env.sh这个文件不存在,但是存在hive-env.sh-template文件,复制一份修改为hive-env.sh即可。 3.使用编译好的hive-hbase-handler-1.2.1.jar替换hive之前lib目录下面的该jar包 这里说的编译主要是解决hive和hbase不兼容的情况下做的,主要是更改pom.xml中的依赖,然后重新编译一下。如果本身安装就是兼容的版本,这步就可以省略了。 将hbase表映射到hive表中配置完上面的内容,就可以做个实验来检查一下了。 1.在hbase中创建一张表 create 'hbase_test','f1','f2','f3'2.加载数据到hbase_test表中 put 'hbase_test','r1','f1:name','zhangsan' put 'hbase_test','r1','f2:age','20' put 'hbase_test','r1','f3:sex','male' put 'hbase_test','r2','f1:name','lisi' put 'hbase_test','r2','f2:age','30' put 'hbase_test','r2','f3:sex','female' put 'hbase_test','r3','f1:name','wangwu' put 'hbase_test','r3','f2:age','40' put 'hbase_test','r3','f3:sex','male'3.创建基于hbase的hive表 create4.查看hive表中的数据 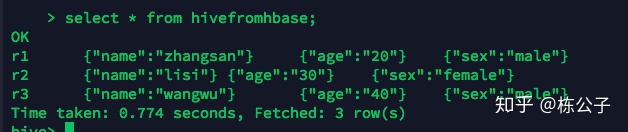
如果您跟我一样也看到如此,那说明您搭建成功了,以后就可以仿照这种情况来做了。比如使用hbase来不断的插入数据,然后遇到比较复杂的sql的查询的时候 就可以用hive来写sql做这个事情,相互配合。 将hive表映射到hbase表中1.创建一张映射hbase的表 create table hive_test( id string, name string, age int, address string )STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:name,f2:age,f3:address") TBLPROPERTIES ("hbase.table.name" = "hbaseFromhive"); 这里的hbaseFromhive表本身hbase没有,也是可以的,他会自动在hbase中创建,所以不再需要在hbase中创建了。2.向hive表中加载数据 这里有些特殊,向hive表中加载的数据来源于另外一张表中。 比如我们创建一个hive_source表 建表语法: create table hive_source( id int, name string, age string address string )row format delimited fields terminated by 't';在Linux本地创建了一个order.txt文件写入下面这些内容 1 zhang 10 M 2 li 20 F 3 mei 30 M 4 wang 40 F 5 guo 60 M注意他们之间的间隔用tab来间隔 然后导入到hive_source表中 load data local inpath 'order.txt' into table hive_source;查看是否导入成功 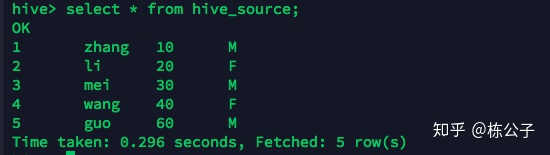
成功之后导入到hive_test表中 insert into table hive_test select * from hive_source;3.在hbase中查看是否已经有数据了 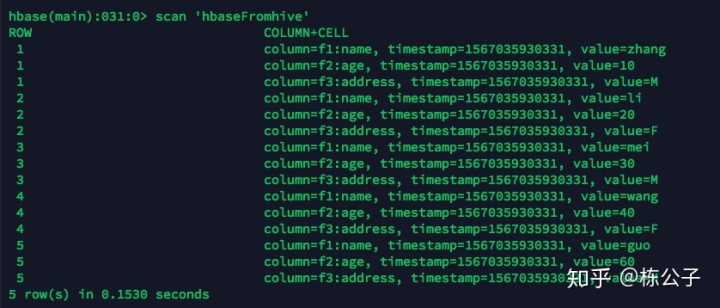
看到这个说明成功了。 总结以上就是全部内容了,点击关注不迷路哟,后续有文章更新也会推送给您,您有什么问题也可以下方留言。 |
【本文地址】